
I recently wrote about the exciting possibilities introduced by Apple’s new coding assistant. Our options for AI-powered development are exploding beyond just ChatGPT, with powerful models from Google, Anthropic, and a growing roster of open-source contenders.
But I’ve found that the general coding leaderboards often feel geared toward web development. Models that score well there don’t always handle iOS-specific frameworks like SwiftUI or The Composable Architecture (TCA), which I use daily.
This led me to a couple of questions. First, which model is actually best for real-world iOS tasks? And second, are premium models like Claude really worth their high API costs? That last one is personal, as I’m hoping my boss will read this article and offer Claude API keys to our team. 😉
To find some answers, I decided to create my own challenge:
The iOS LLM Arena

Let the games begin.
The Contenders
Vision capability was a prerequisite for every model in this comparison, allowing for a direct analysis of the app screenshots. While this feature is standard in the four proprietary models tested, I also included two of the strongest open-source vision models available via Fireworks.ai: Meta’s Llama 4 Maverick and Alibaba’s Qwen2.5-VL. It’s worth noting that while Qwen3 is newer, it’s a text-only model, so it has to sit this round out and wait for the next challenge.
Here are the contenders for Round 1:
| Model | Context Size | Cost | Release Date |
| GPT 4.1 | 1M | $2 (in) / $8 (out) | April 2025 |
| Gemini 2.5 Pro | 1M | $1.25 (in) / $10 (out) | April 2025 |
| Claude Sonnet 4 | 200K | $3 (in) / $15 (out) | May 2025 |
| Claude Opus 4 | 200K | $15 (in) / $75 (out) | May 2025 |
| Llama 4 Maverick Instruct (Basic) | 1M | $0.22 (in) / $0.88 (out) | May 2025 |
| Qwen2.5-VL 32B Instruct | 125K | $0.90 in/out | February 2025 |
‘Context Size’ refers to each model’s memory capacity, and the ‘Cost’ shows the separate price for sending a prompt in versus generating a response out.
My Testing Methodology
My methodology was designed for fairness and repeatability. Every model faced the exact same four UI designs, was driven by a single master prompt, and ran through a fully automated workflow with zero human intervention until it was time to build and run the Xcode project.
The detailed prompt was engineered to elicit professional-grade code using several advanced techniques:
- Role Prompting to make the LLM “think” like a senior iOS developer, not just a text generator.
- Chain-of-Thought reasoning, forcing it to analyze the UI logically before writing a single line of code.
- Few-Shot Examples using code from Apple’s own Scrumdinger app to set a “gold standard” for quality and style.
The Judge’s Scorecard
Each contender was scored on a combination of hard data and expert review to determine the winner.
The Hard Numbers (Quantitative)
- Build Errors on First Compile: How much work is needed to get the code running?
- Total API Cost: What was the precise cost for each generation?
- Token Usage: How efficient was the model?
The Expert Review (Qualitative)
Visual Fidelity: How closely did the result match the original design? To answer this objectively, I went beyond a simple surface-level review. Each design was broken down into a component checklist, rating everything from pixel-perfect layout accuracy down to whether an element was present but needed significant work.
Code Quality & Maintainability: Was the code clean, readable, and structured for real-world use? While this was primarily a visual challenge, the underlying code still matters.
The Challenge Designs
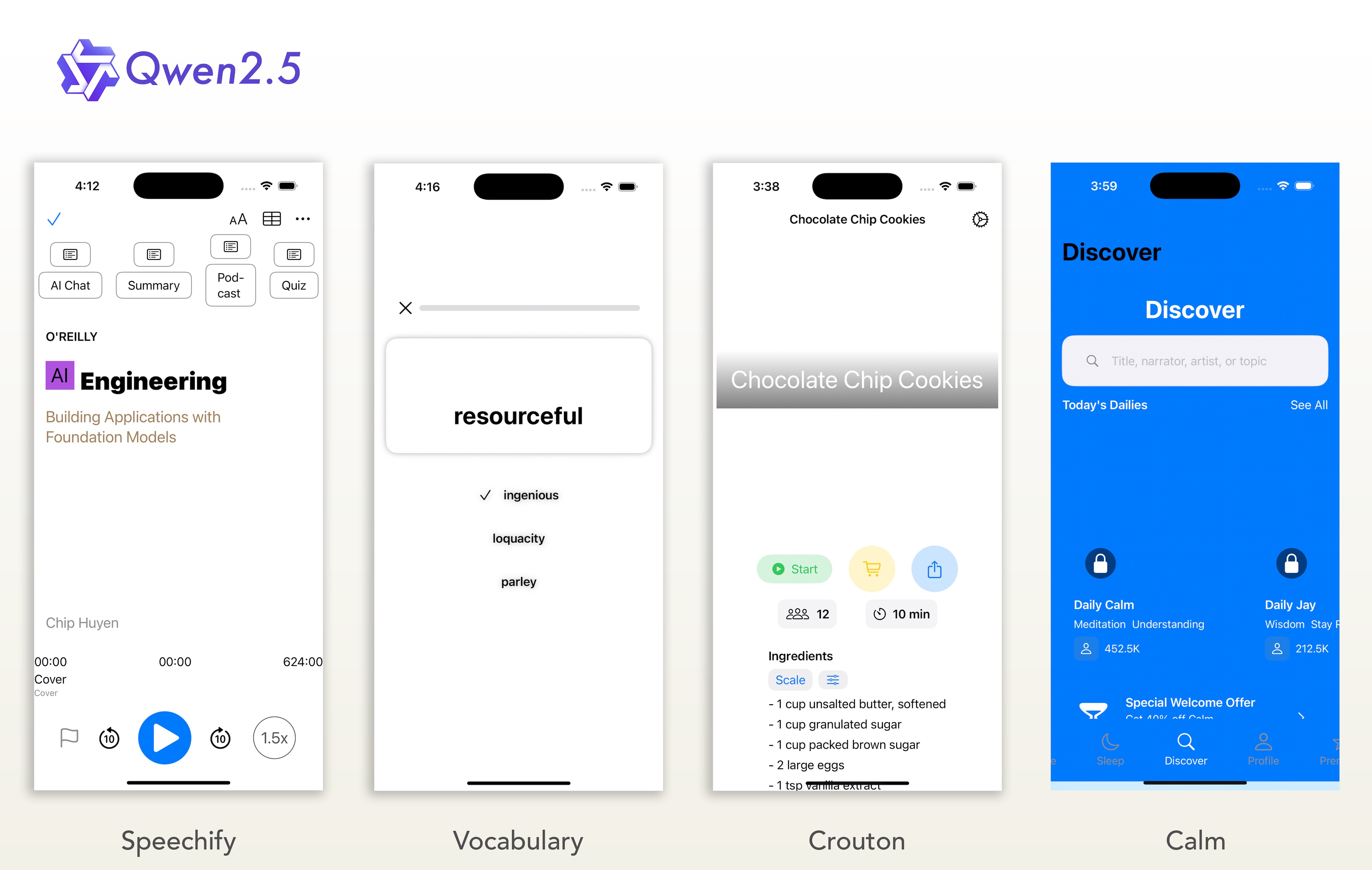
To create a worthy challenge, I selected four beautiful, real-world app designs to serve as the benchmark. To ensure the test reflects the gold standard of the ecosystem, all four are recent Apple Design Award winners. The chosen designs strike a crucial balance: they feel like standard iOS apps but contain just enough custom styling and unique layouts to truly test each model’s attention to detail.
![]()
- Speechify: (App Store) Converts documents, articles, and PDFs into high-quality audio you can listen to on the go to boost focus and productivity.
- Vocabulary: (App Store) A vocabulary-building app that teaches new words in short daily sessions customized to your English proficiency.
- Crouton: (App Store) A sleek recipe organizer and meal-planner app that lets you import recipes from websites, cookbooks or scans and plan your weekly meals.
- Calm: (App Store) The number-one meditation and sleep app with guided meditations, sleep stories, and calming sounds to help you relax.
The Main Event
For each app, you’ll see the original design first, followed by a side-by-side comparison of each contender’s generated UI. Beneath that, I’ll dive into the crucial data from my scorecard, token usage, API costs, and visual ratings. The open-source designs were split out and shown further below.
App #1: Speechify
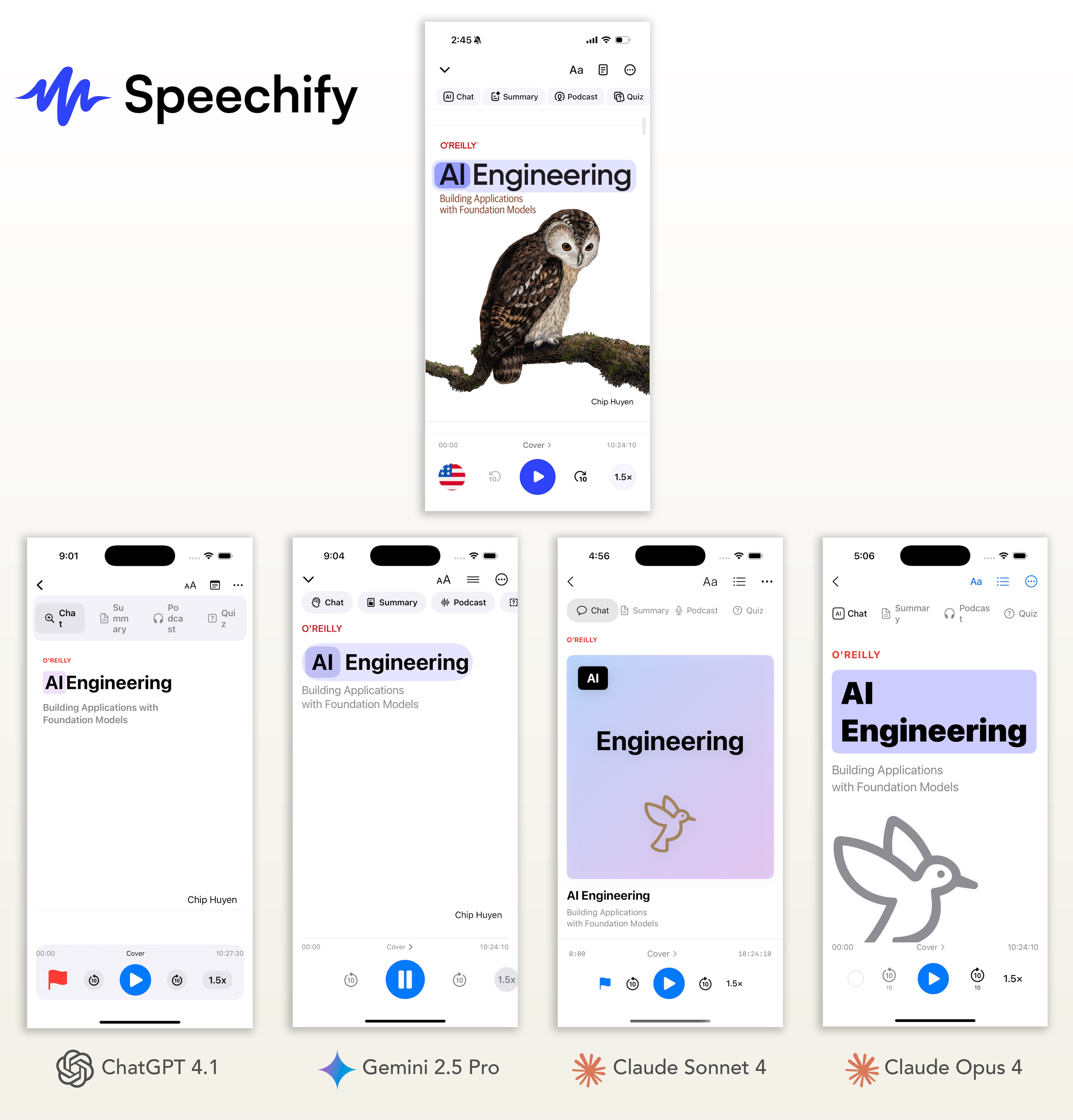
My Analysis
While all the proprietary models performed well, Google Gemini is the clear winner for this challenge. It was the only model to correctly replicate the most complex parts of the design: the highlighting of individual words in the text and the proper styling of the scrolling chip buttons at the top. Although I was impressed that the Claude models attempted to draw the book cover graphic using SF Symbols, they failed on the text-highlighting feature, while Gemini nailed it.
Speechify Token Usage & Cost
| Model | Input Tokens | Output Tokens (+ Thinking) | Total Tokens | Cost | Visual Rating |
| GPT 4.1 | 8,092 | 3,937 | 12,029 | $0.0477 | 3.25 |
| Gemini 2.5 Pro | 7,790 | 3,547 (2,192) | 13529 | $0.0671 | 4.25 |
| Claude Sonnet 4 | 10,111 | 3,466 | 13,577 | $0.0823 | 3.75 |
| Clause Opus 4 | 10,111 | 3,781 | 13,892 | $0.4352 | 3.25 |
| Llama 4 Maverick | 7,623 | 1,869 | 9,492 | $0.0033 | 1.75 |
| Qwen2.5 VL | 7,623 | 2,865 | 10,488 | $0.0094 | 2 |
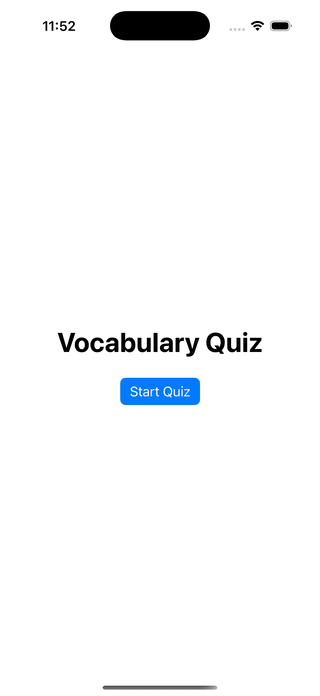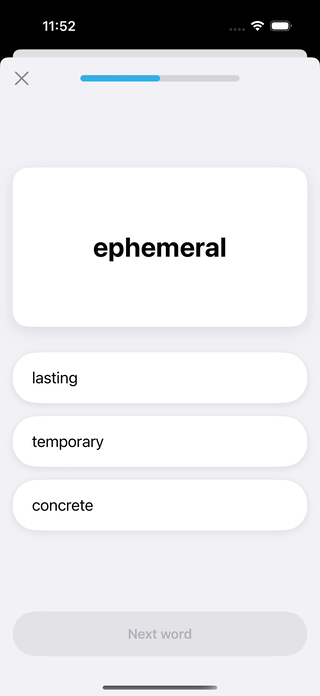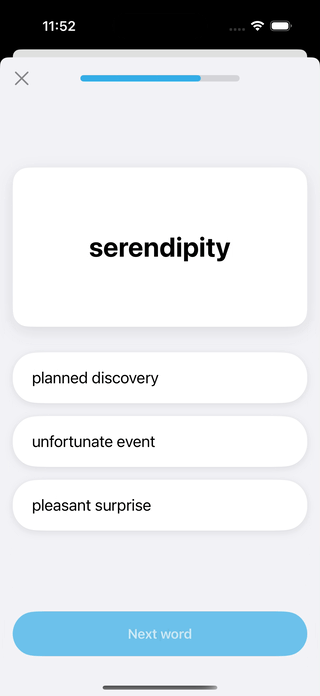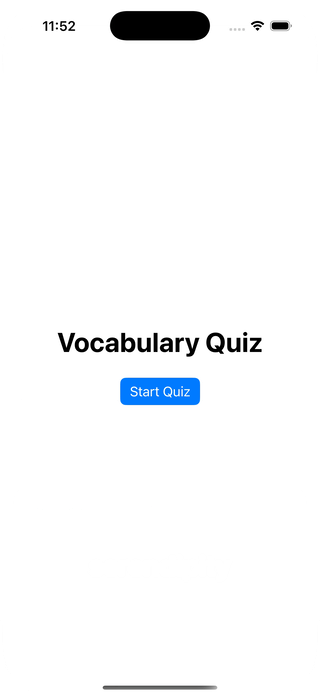
App #2: Vocabulary
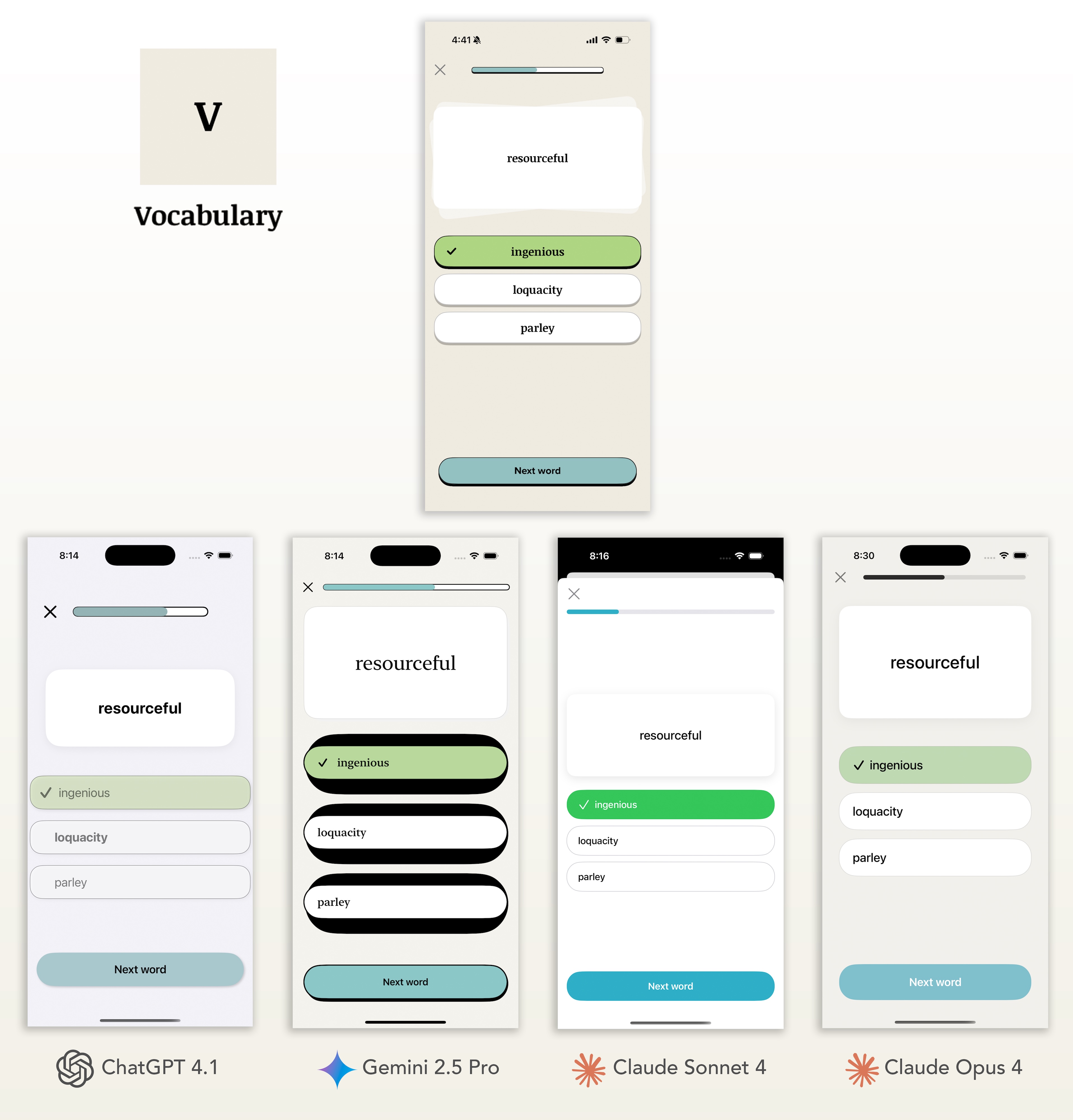
My Analysis
This challenge, with its custom drop shadows and specific color palette, really separated the contenders. At first glance, Google Gemini’s output was an eyesore due to the large black borders on the answer buttons.However, upon closer inspection, I realized this was a flawed attempt at the custom drop shadow, even though the model had perfectly replicated that same shadow on the ‘Next Word’ CTA. Gemini was also the only model to use the correct mix of serif and sans-serif fonts. For nailing the most difficult and nuanced parts of the design, Google Gemini wins this challenge, with Opus coming in a close second.
Claude Sonnet had the weakest UI generation, but while inspecting the code, it became clear that sonnet put more resources into fleshing out the functionality of the app, as you’ll see much further down.
Vocabulary Token Usage & Cost
| Model | Input Tokens | Output Tokens (+ Thinking) | Total Tokens | Cost | Visual Rating |
| GPT 4.1 | 8,092 | 2,728 | 10,820 | $0.038008 | 3 |
| Gemini 2.5 Pro | 7,790 | 3,378 (1,868) | 13,036 | $0.0621975 | 4.25 |
| Claude Sonnet 4 | 10,111 | 2,863 | 12,974 | $0.073278 | 2.5 |
| Clause Opus 4 | 10,111 | 2,724 | 12,835 | $0.355965 | 3.5 |
| Llama 4 Maverick | 7,623 | 1,678 | 9,301 | $0.0031537 | 1.5 |
| Qwen2.5 VL | 7,623 | 2,577 | 10,200 | $0.00918 | 1.25 |
App #3: Crouton
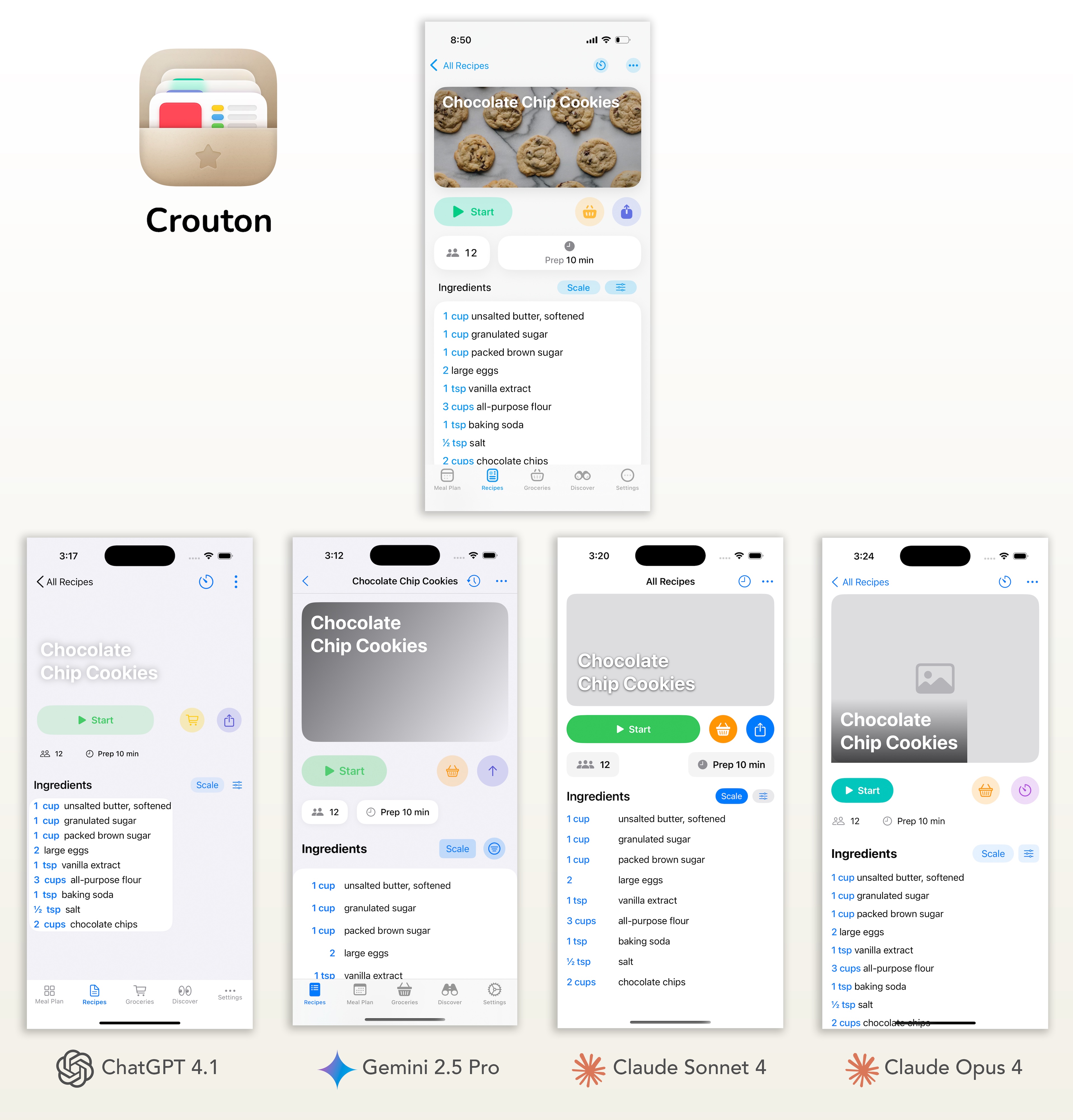
My Analysis
The models showed varied results on this design, but Google Gemini once again emerged as the front-runner, most accurately matching the colors and styling of the key buttons. Its main weakness was in layout and spacing, but they all struggled here. Opus secured second place, while ChatGPT and Claude Sonnet tied for third, as both models missed key styling components. Interestingly, both Claude models completely ignored the tab bar.
Crouton Token Usage & Cost
| Model | Input Tokens | Output Tokens (+ Thinking) | Total Tokens | Cost | Visual Rating |
| GPT 4.1 | 8,092 | 4,175 | 12,267 | $0.0496 | 2.75 |
| Gemini 2.5 Pro | 7,790 | 3,466 (1,610) | 12,866 | $0.0605 | 3.75 |
| Claude Sonnet 4 | 10,111 | 3,684 | 13,795 | $0.0856 | 3 |
| Clause Opus 4 | 10,111 | 3,232 | 13,343 | $0.3941 | 3.25 |
| Llama 4 Maverick | 7,623 | 1,980 | 9,603 | $0.0034 | 1.25 |
| Qwen2.5 VL | 7,623 | 2,801 | 10,424 | $0.0093 | 1.75 |
App #3: Calm
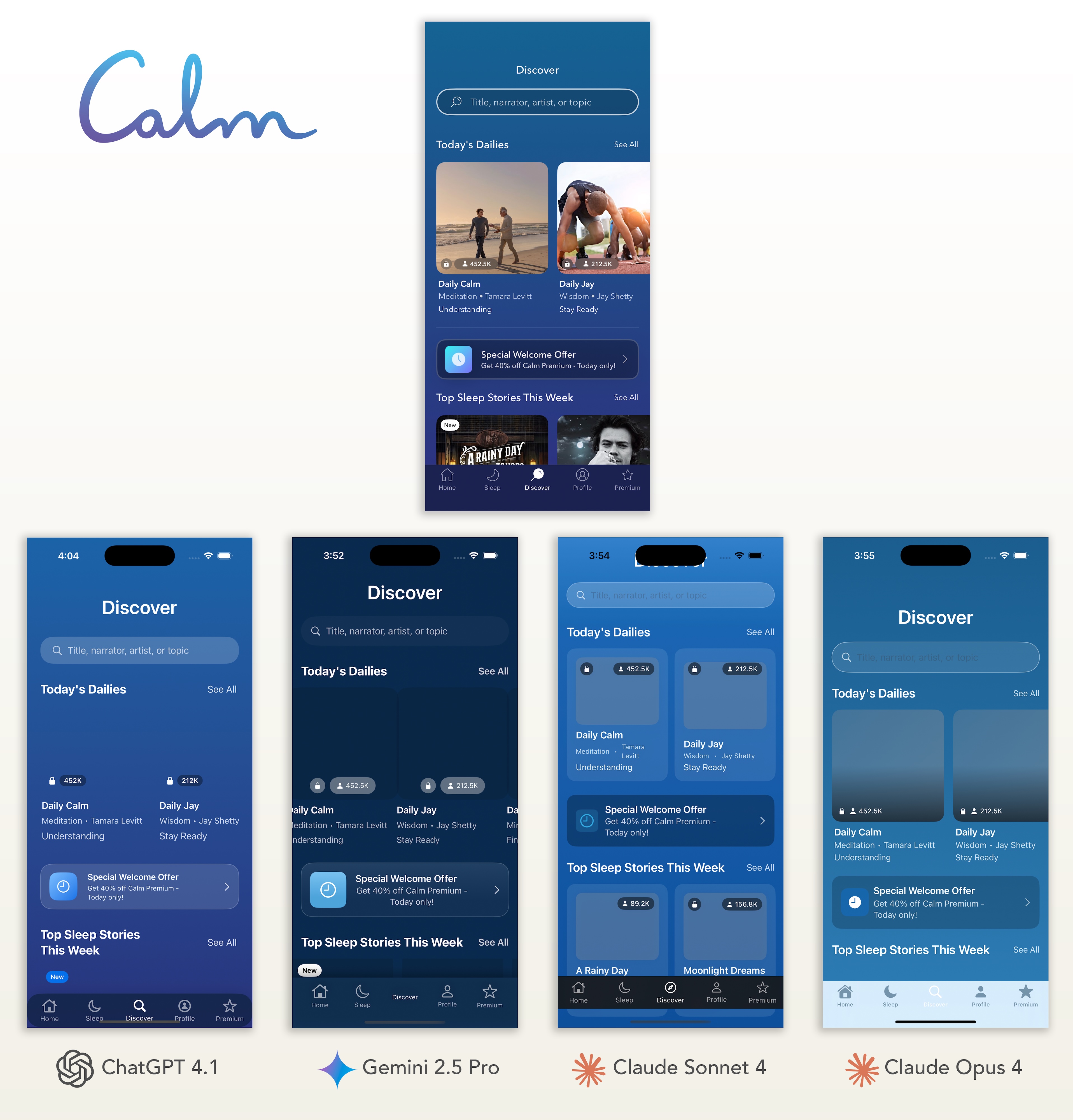
My Analysis
I expected this complex design to create more problems, but I was surprised at how well most models performed, correctly capturing details like the user “like” count and the custom tab bar. The race came down to ChatGPT and Google Gemini, who were both very close on the overall color scheme and styling. I’m giving the slight edge to ChatGPT for one critical reason: Gemini’s final code had a layout bug that cut off the top row of content by default. ChatGPT’s version was correctly aligned, saving a developer from having to fix a frustrating visual bug.
Calm Token Usage & Cost
| Model | Input Tokens | Output Tokens (+ Thinking) | Total Tokens | Cost | Visual Rating |
| GPT 4.1 | 8,092 | 3,715 | 11,807 | $0.0459 | 4.25 |
| Gemini 2.5 Pro | 7,790 | 3,566 (2,354) | 13,710 | $0.0689 | 4 |
| Claude Sonnet 4 | 10,111 | 4,947 | 15,058 | $0.1045 | 2.75 |
| Clause Opus 4 | 10,111 | 4,003 | 14,114 | $0.4519 | 3.75 |
| Llama 4 Maverick | 7,623 | 2,425 | 10,048 | $0.0038 | 1.25 |
| Qwen2.5 VL | 7,623 | 3,317 | 10,940 | $0.0098 | 1.75 |
The Open-Source Division
The performance gap between the leading proprietary models and the open-source alternatives was significant enough that a direct comparison felt misleading. Therefore, to better analyze the unique strengths and weaknesses of the open-source options, this section compares them directly against each other.
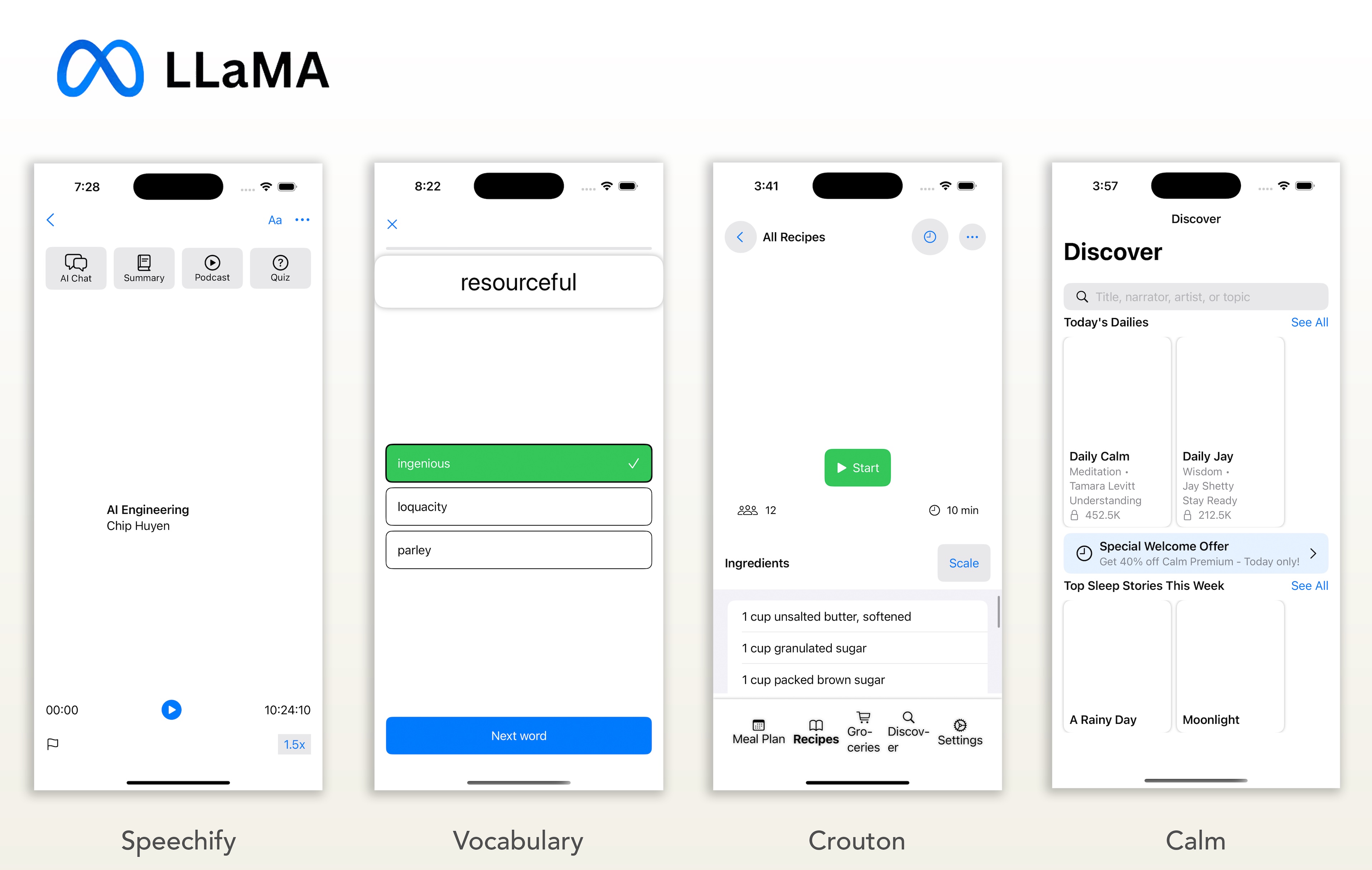
My Analysis
The open-source models are not yet on the same playing field as the proprietary leaders for this specific vision-to-code task, but they show clear potential. The most surprising finding was that Qwen2.5-VL (32B) was consistently comparable to the much larger Llama 4 Maverick (401B) model. Qwen’s performance on the Crouton app’s button styling was particularly impressive, while Llama’s best attempt was on the complex Calm app. I wouldn’t use them for this kind of work today, but they provide an excellent baseline for future tests as new models are released.
The Final Scorecard
After four rounds, here’s how the contenders stacked up based on token usage, cost, and my subjective visual rating.
Final Cost Comparison
| Model | Total Tokens | Cost | Visual Rating |
| GPT 4.1 | 46,923 | $0.181 | 3.3 / 5 |
| Gemini 2.5 Pro | 53,141 | $0.259 | 4 / 5 🏆 |
| Claude Sonnet 4 | 55,404 | $0.346 | 3 / 5 |
| Clause Opus 4 | 54,184 | $1.637 | 3.4 / 5 |
| Llama 4 Maverick | 38,444 | $0.0137 | 1.4 / 5 |
| Qwen2.5 VL | 42,052 | $0.038 | 1.6 / 5 |
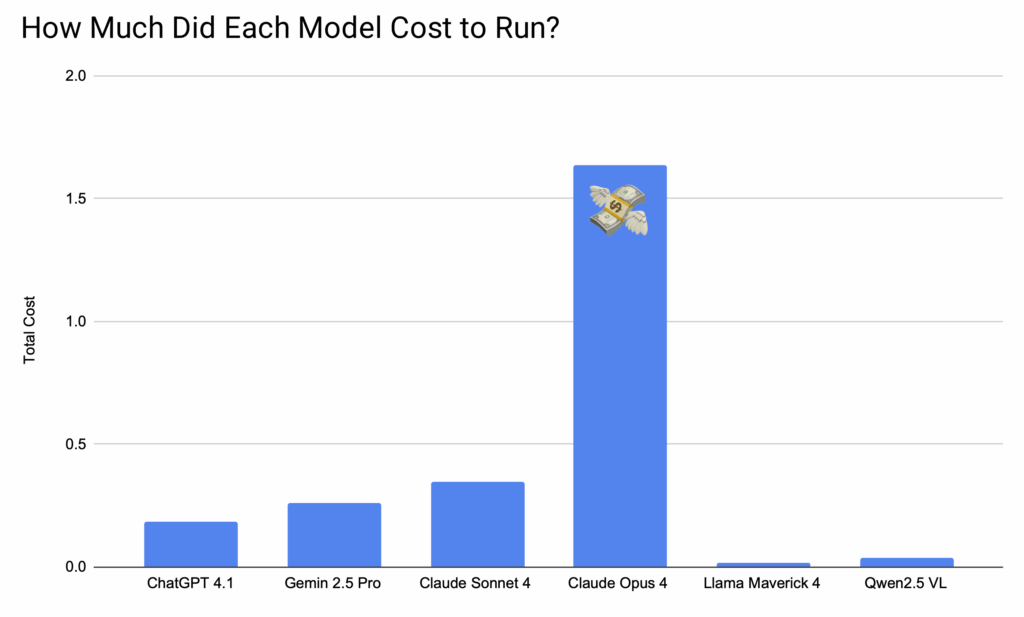
Crowning the Champion

Across all four tests, Google Gemini consistently delivered the most visually accurate UI. It demonstrated a remarkable ability to match colors, layouts, and styles, producing results that were often closest to the original design right out of the box. The code was generally clean and on par with the other top models. For the specific challenge of UI generation, Google’s Gemini 2.5 Pro is the clear winner.
Key Observations
While Gemini excelled at the main task, two other findings are critical for anyone choosing a model for iOS development:
Claude Sonnet’s Unexpected Logic: The most surprising result came from Claude Sonnet. On the Vocabulary app challenge, it produced a relatively weak UI but demonstrated a remarkable ability to infer the application’s purpose, building out a nearly complete, multi-step quiz logic that no other model attempted. Although the instructions were to only implement the visual UI, the model’s behavior suggests a strong aptitude for more complex, logic-based tasks.
Claude Opus’s Cost 🤑: The high price of Claude Opus did not translate to a proportionally higher quality output. Its results were largely on par with Gemini and Sonnet, making it difficult to justify the significant price premium for UI-centric tasks. Whether its premium cost translates to an advantage in logic-intensive challenges is a question for a future round in the arena.
Code Quality Highlights
Here are the most notable findings while reviewing the code produced by the models for each of the four challenges.
For the “Speechify” App:
All the proprietary models produced solid, high-quality code, with GPT-4.1 and Claude Sonnet standing out for their exceptionally clean architecture and view decomposition. In contrast, the open-source models showed promise in their structure, but both Llama 4 and Qwen2.5 shipped with minor but critical compiler errors that prevented them from running out-of-the-box.
For the “Vocabulary” App:
This challenge revealed major differences in code quality. Claude Sonnet produced the highest-rated code, demonstrating excellent architecture and modern practices. Notably, Gemini 2.5 Pro was the only model to implement correct answer validation, preventing users from selecting an incorrect choice, though its code did rely on hardcoded progress values. In contrast, both Llama 4 and Qwen2.5 suffered from potential array-bound crashes, making their code fundamentally unsafe for production.
For the “Crouton” App:
The results were mixed, with most models delivering well-structured but incomplete code full of non-functional buttons and hardcoded values. Claude Opus received the highest score for its strong architectural patterns, while Llama 4 was noted for having potential array-bound crashes and Qwen2.5 for lacking any functional state management, making it more of a static prototype.
For the “Calm” App:
On this complex design, code quality varied widely. Google Gemini produced the most solid, well-structured code, though it needed minor refactoring for layout hacks. Llama 4‘s submission, in contrast, relied on several outdated, deprecated SwiftUI APIs requiring modernization.
The links to the generated source code can be downloaded below.
Unaltered Xcode Projects
| ChatGPT 4.1 | Speechify | Vocabulary | Crouton | Calm |
| Gemini 2.5 Pro | Speechify | Vocabulary | Crouton | Calm |
| Claude Sonnet 4 | Speechify | Vocabulary | Crouton | Calm |
| Claude Opus 4 | Speechify | Vocabulary | Crouton | Calm |
| Llama 4 Maverick | Speechify | Vocabulary | Crouton | Calm |
| Qwen2.5 VL | Speechify | Vocabulary | Crouton | Calm |
Final Verdict & Future Arenas
This experiment turned out to be both fun and eye-opening. My initial hunch that some AI models have a natural talent for iOS development was validated, just not in the way I expected. I expected the premium-priced Claude Opus to dominate the competition, but its performance was merely on par with the others. I also suspected ChatGPT might be a weaker contender for SwiftUI, possibly iOS in general, and this challenge seemed to support that theory. This is particularly ironic given that ChatGPT is the default model for Apple’s new Xcode assistant, which thankfully makes it easy to use alternate models.
This is just the first round. I’ll continue to iterate on the testing process: sharpening the prompts, streamlining the automation, and refining the scoring metrics to ensure an even more rigorous analysis next time. Stay tuned for the next challenge in the iOS Arena.
My goal is to eventually make this automation flow public for others to run their own side-by-side comparisons. I’m currently refining the evaluation process and exploring cost-effective ways to manage the API fees required for a public tool. Stay tuned for updates on this front.
Get Involved!
What frameworks or challenges should I tackle after TCA? Should the models build a networking layer? Handle complex animations? Your ideas will shape the future of the arena.
Let me know your thoughts on Mastodon: @ronnierocha